

Evaluating Model Performance
By Roscoe Kerby, 19 May 2023
Computer Scientist working as a Software Engineer. [BSc Computer Science Honours, BSc Mathematical Science (Computer Science)] [runtime.withroscoe.com]
Understanding Confusion Matrix, Recall, Precision, Feature Importance, and the Recall vs Precision Trade-off Curve in AI and ML
Basic AI/ML Model Evaluation Metrics
Introduction
In the realm of Artificial Intelligence (AI) and Machine Learning (ML), the evaluation of model performance is crucial for assessing the effectiveness and reliability of predictive models. Evaluation metrics provide a quantitative measure of how well a model performs, enabling us to make informed decisions and improve our algorithms.
This article will explore key evaluation metrics such as the Confusion Matrix, Recall, Precision, and Feature Importance. Additionally, it will delve into the trade-off between Recall and Precision, and the significance of the threshold in model evaluation.
Confusion Matrix
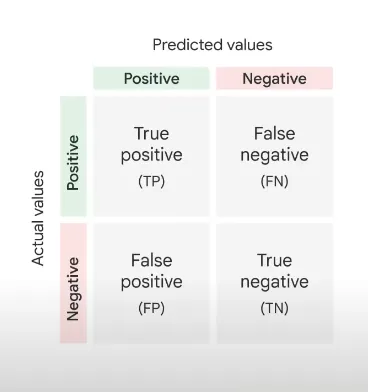
The Confusion Matrix is a table that allows us to visualize the performance of a classification model. It presents a summary of the predicted and actual values for a given dataset. The matrix is divided into four sections: True Positives (TP), False Positives (FP), False Negatives (FN), and True Negatives (TN). TP represents the cases where the model correctly predicted the positive class, while TN denotes the cases where the model correctly predicted the negative class. Conversely, FP signifies the instances where the model predicted the positive class incorrectly, and FN represents the cases where the model predicted the negative class incorrectly.
Recall (Sensitivity)
Recall, also known as Sensitivity or True Positive Rate (TPR), measures the model’s ability to correctly identify positive instances out of the total actual positive instances. It is computed as the ratio of TP to the sum of TP and FN:
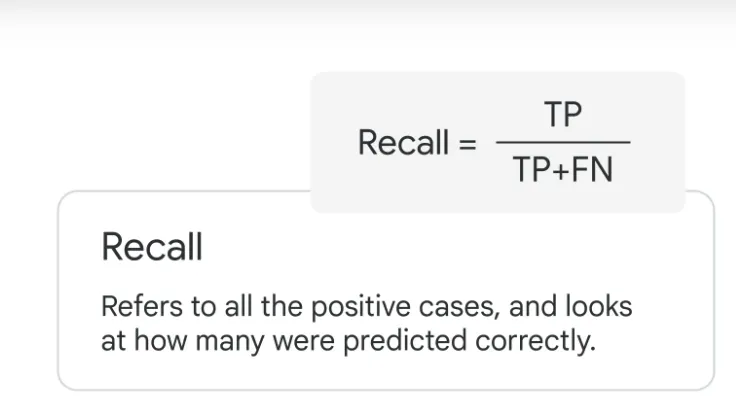
Recall = TP/(TP +FN)
Recall provides valuable insights into a model’s ability to capture positive instances, minimizing the risk of false negatives. In medical diagnostics, for instance, recall is vital as it ensures that actual positive cases are not missed, even if it results in a higher number of false positives.
Precision
Precision, often referred to as Positive Predictive Value (PPV), gauges the model’s ability to correctly predict positive instances out of all predicted positive instances. It is calculated as the ratio of TP to the sum of TP and FP:

Precision = TP / (TP + FP)
Precision emphasises the quality of positive predictions. A higher precision indicates a lower number of false positives, implying that when the model predicts a positive instance, it is likely to be correct. In situations where false positives are costly or lead to unnecessary actions, precision becomes a critical evaluation metric.
Feature Importance
Feature Importance refers to the analysis of the relative importance of different input features in influencing the model’s predictions. It helps us understand which features contribute most significantly to the model’s decision-making process. Various techniques, such as permutation importance, feature importance from tree-based models (e.g., Random Forests, Gradient Boosting), and coefficients from linear models, can be employed to determine feature importance. By identifying the most influential features, we can gain insights into the underlying patterns and enhance the interpretability of the model.
Recall vs Precision Trade-off Curve and Threshold
Recall and Precision are inversely related evaluation metrics, meaning improving one may lead to a decline in the other. The trade-off between Recall and Precision can be visualised using a trade-off curve. This curve demonstrates the relationship between different classification thresholds and the corresponding Recall and Precision values.
When the classification threshold is set high, the model becomes more conservative and tends to predict fewer positive instances, resulting in higher Precision and lower Recall. Conversely, lowering the threshold makes the model more permissive, predicting more positive instances, which may lead to higher Recall but lower Precision.
Selecting an optimal threshold depends on the problem context and the importance assigned to Recall and Precision. For example, in fraud detection, maximising Recall is often crucial to identify as many fraudulent cases as possible, even if it means having a higher number of false positives. On the other hand, in a spam email classification system, precision may take precedence to ensure that legitimate emails are not wrongly classified as spam.
Conclusion
In summary, evaluation metrics such as the Confusion Matrix, Recall, Precision, and Feature Importance, along with understanding the trade-off between Recall and Precision, play pivotal roles in the evaluation of AI and ML models.
By leveraging these metrics effectively, we can make informed decisions, improve our models, and ultimately build more accurate and reliable AI systems that drive meaningful results.
#thedatacompany #artificialintelligence #machinelearning #Mlops
Roscoe Kerby, BSc Computer Science Honours, BSc Mathematical Science (Computer Science)

