

Insurance AI is Expensive
The Most Expensive Problem in Insurance AI Is Not The Model. It Is The Mess Before The Model.
Everyone is talking about AI in insurance.
Copilots. Agents. Automation. Faster underwriting. Smarter claims. Better service.
And yes, the opportunity is real.
McKinsey is right to point out that generative AI is already beginning to reshape document-heavy insurance work such as policy issuance, submissions and parts of claims handling. But the same body of work also makes something else clear: only a small number of insurers have extracted outsize value so far.
Why?
Because most insurers do not really have an AI problem.
They have a first-mile problem.
The documents arrive in twenty formats.
The bordereaux is incomplete.
The submission pack is inconsistent.
The claims notes sit in free text.
The email chain contains the key context.
The attachment naming makes no sense.
The team compensates with judgement, spreadsheets, rekeying and workarounds.
Then we ask AI to sit on top of that and somehow produce clean, auditable, scalable value.
That is where many programmes start to wobble.
The real bottleneck is operational ambiguity
Across insurance, leaders are under pressure to do two things at once: improve efficiency and modernise how work gets done. KPMG’s recent research shows insurers are prioritising embedding AI into new ways of working, improving data and analytics capabilities, addressing cyber security and fraud, and managing regulation and risk convergence. The same research also shows only 25 percent of transformation and cost initiatives are considered highly successful.
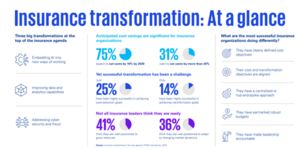
Source:KPMG
That should tell us something.
The market does not need more AI theatre.
It needs operational redesign that can survive contact with real insurance work.
Not a demo.
Not a lab use case.
Not a slide saying “agentic”.
Actual production conditions.
That means starting where value is most often lost:
- intake
- extraction
- validation
- exception handling
- workflow routing
- auditability
If the first mile is weak, the rest of the AI stack becomes expensive decoration.
Insurance is moving towards modular value, not giant promises
This is especially visible in the London Market.
The Lloyd’s Market Association has been explicit about the direction of travel for 2026: smaller quick-win projects, shared connection platforms, ACORD-compliant standards and rollout of the Core Data Record across claims, delegated authority and underwriting. In other words, the market is moving towards interoperability and common language, not waiting for one giant transformation event to deliver everything.
That matters far beyond the London Market.
Because it reflects a wider truth in insurance transformation:
The winners are not the firms with the flashiest AI narrative.
They are the firms that can turn messy operational input into trusted, usable, workflow-ready data.
That is what makes automation bankable.
Where insurers should start
If I were sponsoring AI in an insurer, MGA or broker today, I would not begin by asking, “Which model should we use?”
I would begin with four tougher questions.
- Where is human effort still being spent just making information usable?
Not decision-making. Not customer empathy. Not risk judgement.
Just making information usable.
If highly paid people are still cleaning, chasing, retyping, reconciling and interpreting inbound material, there is usually an immediate value case.
- Which document-heavy workflow is closest to economic pain?
Claims intake. Submission triage. Bordereaux validation. Policy checking. Renewal preparation. Complaint handling.
The right starting point is rarely the most glamorous use case. It is usually the one with the clearest operational leakage.
- Where does confidence break down?
Good AI operating models do not pretend uncertainty does not exist.
They score confidence.
They route exceptions.
They keep humans in the loop where ambiguity matters.
They log what happened and why.
That is how you get trust.
Databricks has been making the same broader point in its insurance governance work: scalable AI in insurance requires formal controls, transparent monitoring, auditable processes and unified governance across the lifecycle.
- Can the output plug into the way the businessactually works?
This is the killer question.
If extracted data does not align to the target workflow, the downstream system, the common data model or the reporting standard, the insurer has not automated work. It has simply moved the mess downstream faster.
What ‘better’ looks like
The strongest insurance AI programmes I have seen do not start with magic.
They start with discipline.
They pick one workflow with clear economics.
They map the true intake reality.
They define the target data shape.
They create confidence-scored extraction.
They build exception handling around real business tolerance.
They measure leakage, straight-through processing, cycle time and quality.
Then they scale.
That is also consistent with what insurers themselves are saying. KPMG’s State of AI in Insurance work highlights efficiency and improved quality as the biggest opportunities, while also noting that digitising non-digital information such as phone calls and OCR-based inputs is central to the next step of transformation. It also stresses that without clear use case focus, AI efforts become fragmented and ineffective.
So no, the first move is not “deploy more AI”.
The first move is:
Stabilise the front door of the process.
Because AI fails at ingestion long before it fails at reasoning.
The commercial question boards should be asking now
A lot of boards are still asking whether AI matters.
That is yesterday’s question.
The better question is:
Where are we losing value because our inbound operational data is too messy, too manual or too untrusted to automate safely?
That is a board-level question because it affects:
- cost to serve
- speed to decision
- claims handling efficiency
- underwriting throughput
- operational resilience
- compliance posture
- confidence in reporting
- vendor dependence
And it is increasingly urgent.
KPMG reports that insurers are trying to bring combined ratios down, improve pricing agility through AI and enhanced data and analytics, and improve customer experience, while many also plan to accelerate cost reduction efforts. At the same time, insurers remain highly alert to compliance, security and vendor dependence risks in AI.
That combination changes the brief.
The conversation is no longer “Should we experiment with AI?”
It is “Which workflow can we make more trusted, more efficient and more scalable in the next 90 days?”
That is a much better buying conversation.
Final thought
The future of insurance AI will not be decided by who talks most confidently about agents.
It will be decided by who can operationalise trust.
Who can take submissions, bordereaux, claims documents, emails, calls and attachments and turn them into clean, governed, workflow-ready data.
Who can do that with clear human oversight.
Who can evidence quality.
Who can align to market standards.
Who can show measurable operational value, not just model output.
That is where the real commercial advantage sits now.
And that is where The Data Company is focusing its energy.
References
- https://www.mckinsey.com/industries/financial-services/our-insights/ai-in-insurance-understanding-the-implications-for-investors
- https://assets.kpmg.com/content/dam/kpmg/mt/pdf/2026/01/insurance-transformation-the-new-agenda.pdf
- https://lmalloyds.com/lloyds-market-association-declares-2026-year-of-significant-transition-in-handling-of-market-operations/
- https://www.databricks.com/blog/setting-stage-ai-governance-insurance-2025
- https://assets.kpmg.com/content/dam/kpmg/nl/pdf/2026/state-of-ai-in-insurance-2026.pdf
#DataIngestion #OperationalExcellence #IntelligentDocumentProcessing #UnstructuredData #WorkflowAutomation #LondonMarket #LloydsOfLondon #InsurTech #InsuranceTransformation #DataGovernance #AIStrategy #PragmaticAI #BusinessValue #CombinedRatio

